Stoomboot cluster
Aim: Describe how to access and use Nikhef's Stoomboot cluster.
Target audience: Users of the Stoomboot cluster.
Introduction
The Stoomboot cluster is the local computing facility at Nikhef. It is accessible for users from scientific groups to perform, for example, data analysis or Monte Carlo calculations.
The Stoomboot cluster is comprised of:
- 52 batch nodes with a total of 1952 CPU cores (as of 2023-02-23)
- 3 interactive CPU nodes
- 2 interactive GPU nodes
- 7 GPU batch nodes
A combination of the Torque resource manager and the Maui scheduler are used to distribute work across these nodes. This is called a batch system. All nodes are running a CentOS 7 Linux operating system.
The dCache, home directories, /project and /data storage systems are all accessible from any node in the Stoomboot cluster.
Usage
Access and Use
The Stoomboot cluster can be accessed from the
- CT-managed desktop machines
- interactive nodes
- login nodes
- eduVPN with institute access
Access to the interactive nodes is via ssh.
Batch processing
Most of the detailed information about batch processing and jobs can be found on the batch jobs page.
The bulk of compute power is organized in a batch system. It is suitable for work that is not interactive and can be split up in independent jobs that will last for several hours up to several days.
Batch jobs wait in the queue until the scheduler find a suitable slot for processing.
Seeing what your jobs are doing
The status of all jobs (queued, running, completed) is available via qstat commands from the time of job submission until 600 seconds after the job has completed. For a more global overview, there is a monitoring page available that summarizes properties of each user's jobs for the last day (more specifically, since midnight).
Cluster activity
Real-time activity for the cluster. Click on the graphs to enlarge the image.
STBC use by group
| per Hour | per Day |
|---|---|
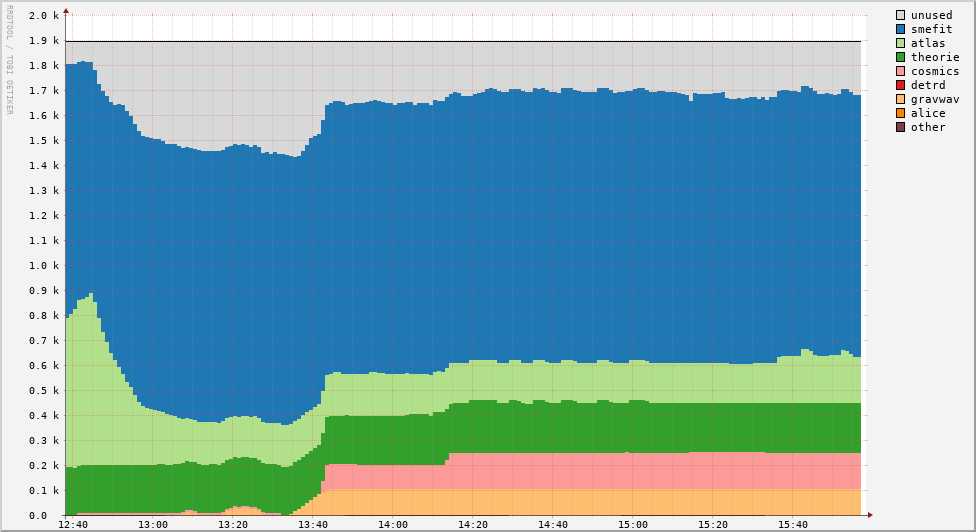 | 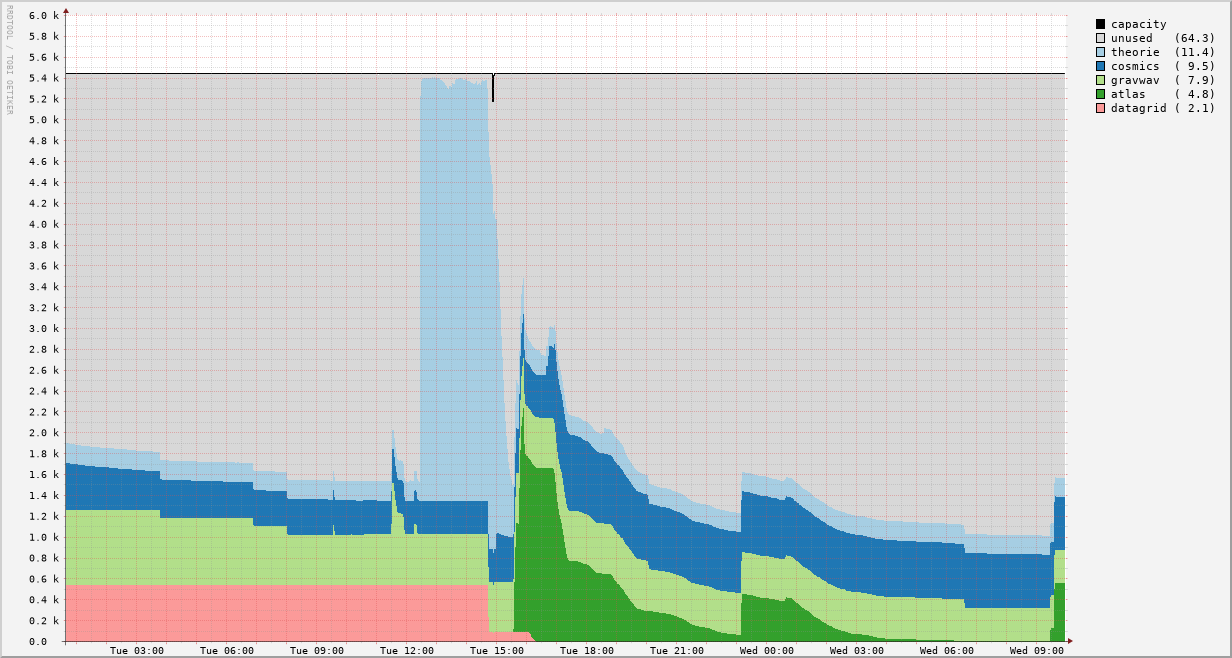 |
Waiting jobs
| per Hour | per Day |
|---|---|
 | 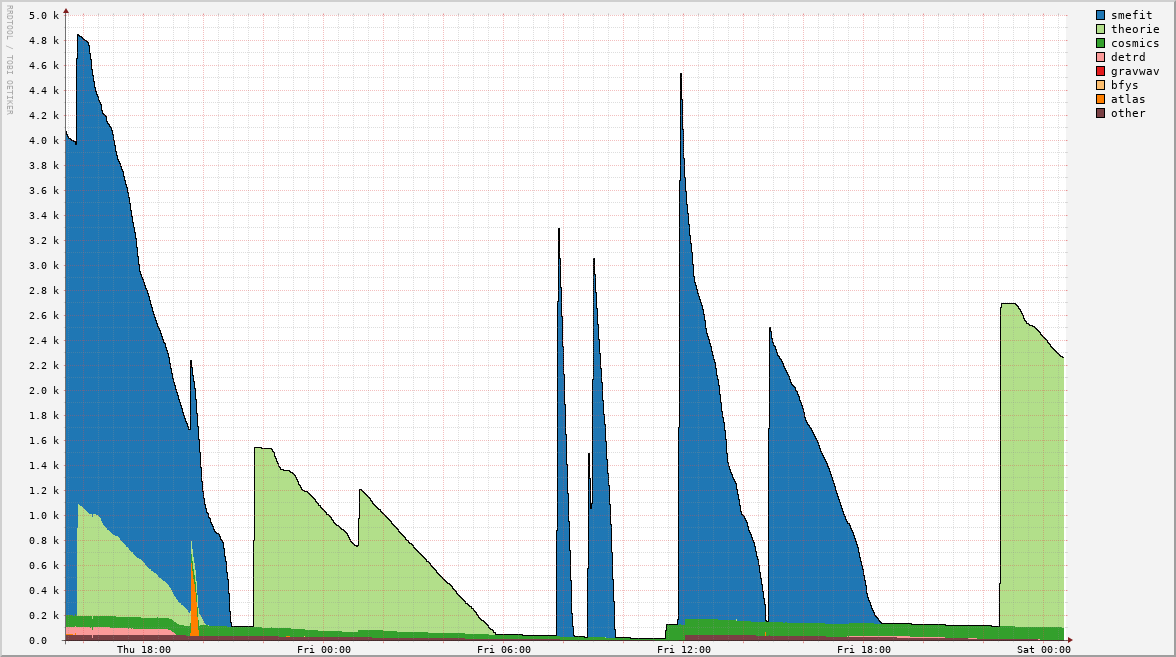 |
Job waiting times
| per Hour | per Day |
|---|---|
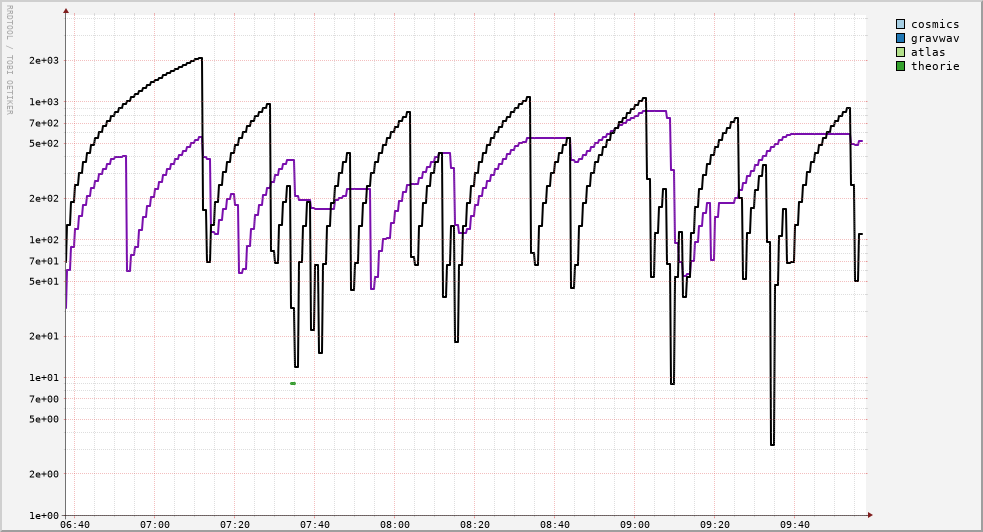 | 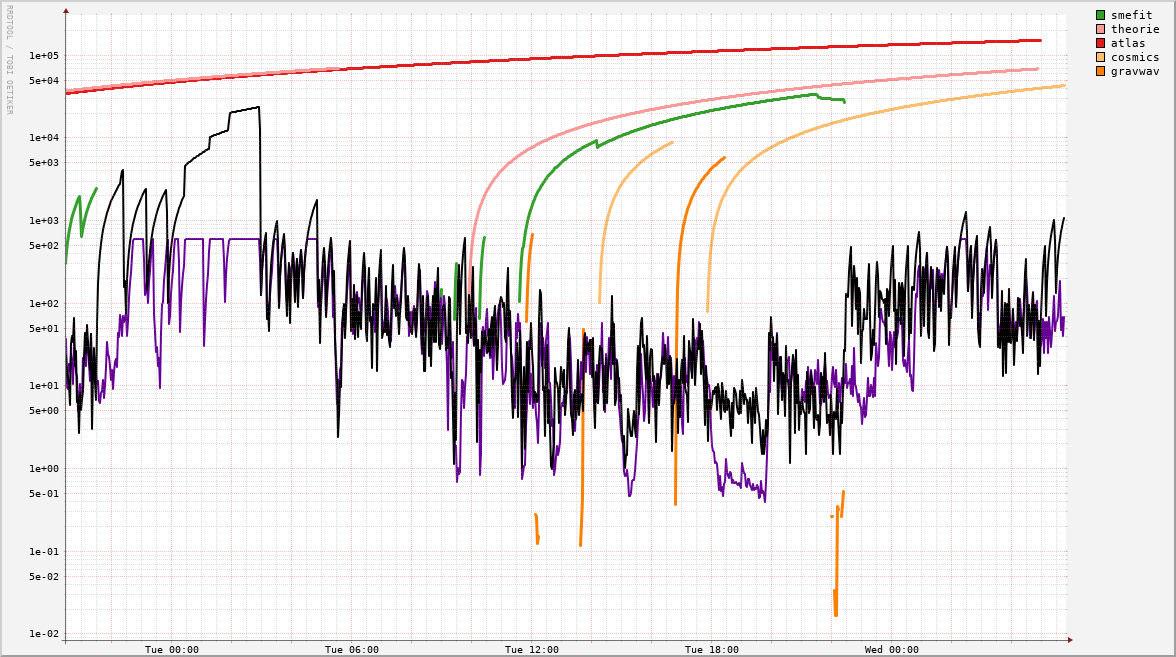 |
Note: The black line shows the time since the most recent job started. The purple line shows the mean time between job exits (inverse of the core rollover rate).
Links
- Stoomboot Cluster Graphs
- How to create, submit and manage batch jobs
- Interactive nodes
- Login nodes
- eduVPN with institute access
- Information about storage options at Nikhef
Contact
- Email stbc-users@nikhef.nl or stbc-admin@nikhef.nl for questions about the Stoomboot cluster.
- Chat in Nikhef's Mattermost channel for stbc-users.